实战拆解:用 n8n 构建 GitHub 热门项目排行榜自动更新系统
1. 引言:当自动化遇上开源数据
在信息爆炸的时代,获取高质量的数据并高效分发是内容创作者、开发者和运营人员的共同需求。GitHub 作为全球最大的开源社区,蕴藏着无数有价值的项目。然而,如何自动化获取高星项目、分类整理,并实时推送到数据库或表单中,成为一个颇具实用性的自动化场景。
n8n,这款开源的工作流自动化平台,凭借「低代码 + 可视化 + 可自托管」的特性,为开发者提供了一个高自由度的自动化工具箱。今天,我们就来拆解一个真实的 n8n 工作流——自动采集 GitHub 热门项目排行榜,并写入飞书多维表格(Bitable)。
2. 工作流概览:从 GitHub 到飞书,一键生成排行榜
📌 目标:定时获取 GitHub 上 stars 数在某区间(如 3000~5000)之间的热门项目,并将结果存入飞书表格,形成一个可视化的排行榜数据库。
📌 关键能力:
- Redis 存储上下文,实现区间分页(stars 分段查询)
- GitHub API 数据抓取与过滤
- 多项目数据拆分处理
- 飞书 Bitable API 写入
- 动态更新 Redis 查询区间,实现增量刷新
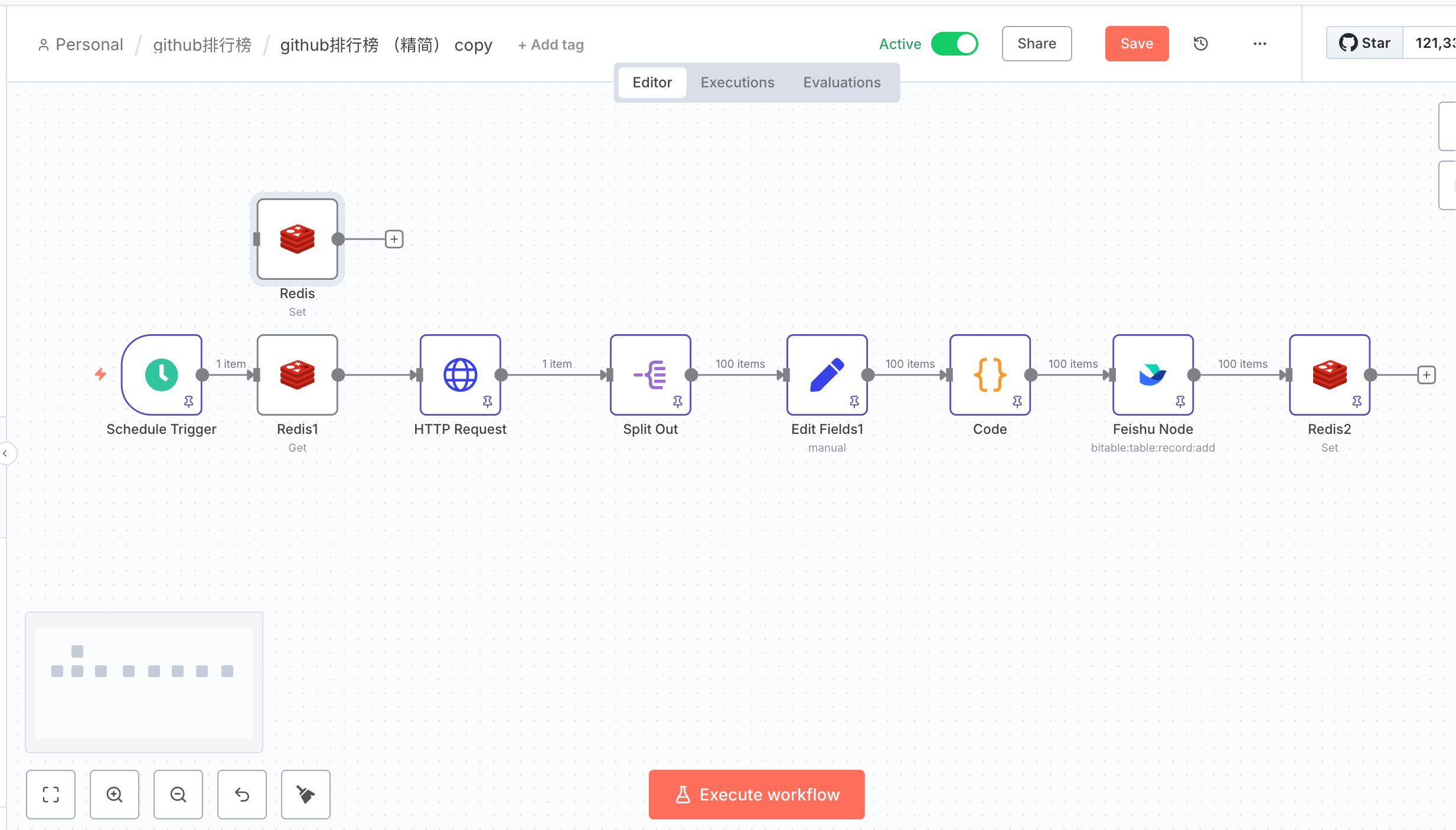
3. 核心流程解析
下面我们分步骤拆解整个流程逻辑:
🧩 Step 1:定时触发 - Schedule Trigger
- 作用:每隔一段时间自动运行(配置为按分钟)
- 功能定位:是整个工作流的“心跳”
🧩 Step 2:Redis 获取上次查询区间 - Redis1
- 操作:
GET star - 作用:从 Redis 获取上一次存储的星标范围(例如
"3000..5000"),用于构造下一步的 GitHub 查询参数
🧩 Step 3:HTTP 请求 GitHub API - HTTP Request
-
请求地址动态构建:
https://api.github.com/search/repositories?q=stars:{{ $json.start }}&sort=stars&order=desc&per_page=100&page=1 -
动态参数:
start来自 Redis(即 stars 区间)
🧩 Step 4:拆分列表数据 - Split Out
- 作用:把 GitHub API 返回的
items数组逐条拆分为单项,便于后续处理
🧩 Step 5:字段清洗与提取 - Edit Fields1(Set 节点)
- 提取字段:
name,html_url,description,stargazers_count - 作用:结构化整理字段,统一输出数据格式
🧩 Step 6:数据转格式 - Code
- 类型:JavaScript 执行节点
- 作用:构建符合 Feishu Bitable 的写入格式
return items.map(item => {
const data = item.json;
return {
json: {
body: JSON.stringify({
fields: {
title: data.name,
star: data.stargazers_count,
github: data.html_url,
description: data.description
}
})
}
};
});
🧩 Step 7:写入飞书表格 - Feishu Node
- 接口操作:调用飞书 Bitable 插入记录
- 参数配置:
app_token和table_id来自飞书后台body是步骤 6 中构造好的字段 JSON
🧩 Step 8:更新 Redis 区间 - Redis2
- 操作:
SET star = 3000..{{ 当前记录最大星数 }} - 目的:动态更新下次查询的起始 stars 区间,实现分页式递进更新
4. 技术亮点解析
✅ Redis 状态控制
工作流中巧妙地使用 Redis 存储 stars 区间,模拟分页查询,避免重复抓取。这在采集类任务中是非常关键的设计模式。
✅ GitHub API 高阶查询
使用 q=stars:3000..5000&sort=stars 构造高级查询语法,有效过滤数据,精确获取目标项目。
✅ 动态数据构造 + JavaScript 格式转换
通过 Code 节点构建 JSON body,可灵活适配飞书 Bitable 的结构,非常适合结构化输出需求。
✅ 飞书自定义节点调用
利用社区节点 feishu-lite 对接 Bitable 表格,实现企业内部协作数据更新,满足跨团队信息同步需求。
5. 总结与扩展思路
这个工作流充分展示了 n8n 在“数据抓取 - 清洗 - 写入 - 状态控制”方面的强大能力,尤其适合以下场景:
- 定时榜单类内容自动更新(如热搜榜、项目推荐、文章排行)
- 结构化 API 抓取并入库
- 与 Redis 搭配构建有状态的增量抓取系统
🔧 进阶玩法建议:
- 接入飞书群机器人,每天定时发送 GitHub Top 项目列表
- 拓展多语言分类榜单(如 Python/JavaScript),通过 IF 条件分支筛选
- 增加 GPT 总结节点,对项目描述进行摘要再上传